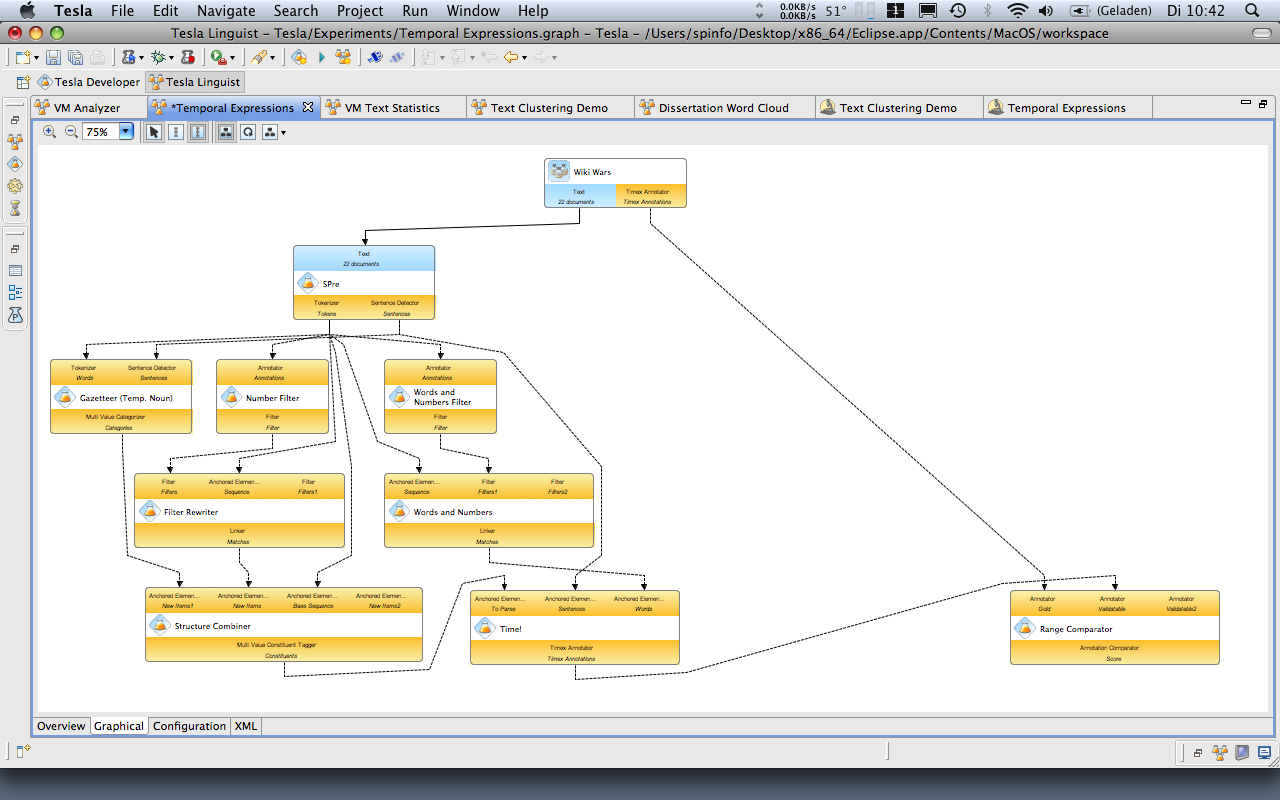
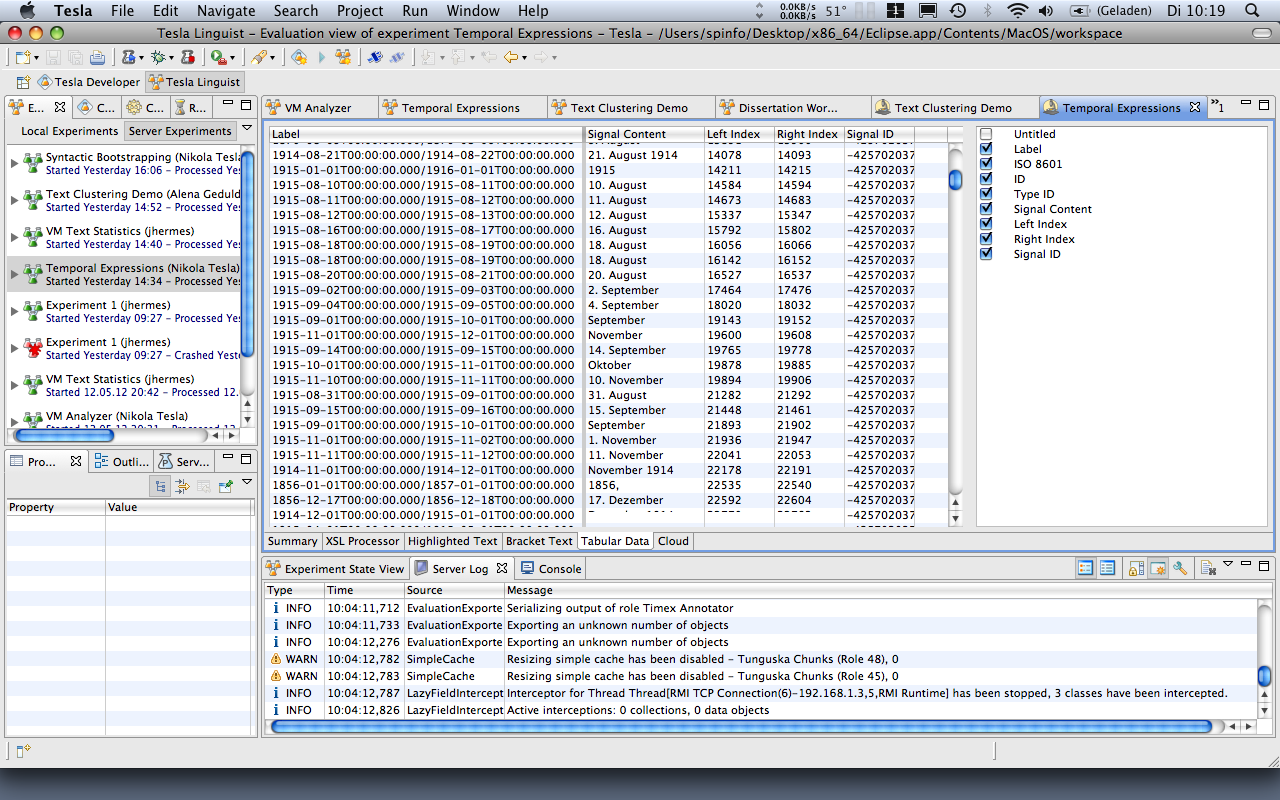
Vor ungefähr drei Jahren war ich mit meiner Promotion an einen Punkt gelangt, an dem ich die Entscheidung treffen musste, in welche Richtung sich meine Dissertation weiterentwickeln sollte. Wir hatten unser System Tesla schon zu einem guten Teil realisiert, die Darlegung zur Motivation der Entwicklung eines eigenen Komponentensystems – die Idee wirklich reproduzierbarer Experimente auf Textdaten beliebigen Formats – lag auch bereits in einer Rohform vor. Was fehlte, war ein Anwendungsfall, an dem ich die Funktionalität des Systems bestmöglich demonstrieren konnte. Und die Suche nach einem solchen geeigneten Untersuchungsobjekts hatte mich schon eine ganze Zeit beschäftigt. Eher zufällig stöberte ich dabei nochmal in einem Buch, dessen Lektüre bei mir schon etwas weiter zurücklag: Im wirklich empfehlenswerten Lexikon des Unwissens von Kathrin Passig und Aleks Scholz.1
Dabei fiel mir auf, dass das Voynich-Mauskript (VMS), dem im Lexikon ein Eintrag gewidmet ist, ein durchaus geeignetes Thema wäre, um die Anwendbarkeit von Tesla zu demonstrieren:
- Das VMS enthält einen Text. Mit unbekannten Zeichen geschrieben, unbekannten Inhalts und unbekannter Herkunft. Aber einen Text. Und wir haben Tesla entwickelt, um sämtliche Texte analysieren zu können. Auch wenn der VMS-Text auf seine Art einzigartig ist, er sollte sich mit Tesla analysieren lassen.
- Die Analysen zu VMS sind genauso zahlreich wie auch widersprüchlich. So gut wie alle denkbaren Theorien zur Herkunft oder Inhalt des Textes lassen sich irgendwo finden. Die glaubhaften Analysen einmal in einem System zu bündeln, in dem sie für die ganze Welt reproduzierbar sind, sollte nicht schaden.
- Das VMS reizt natürlich auch durch seine geheimnisvolle Aura. Damals schon 97 Jahre zerbarsten daran die Theorien durchaus (bisweilen überaus) intelligenter Wissenschaftler und Nicht-Wissenschaftler, ohne dass jemand tatsächlich eine allgemein anerkannte Lösung zum Problem hatte liefern können.
Der Anspruch, den Text tatsächlich entschlüsseln zu können, wäre natürlich allzu vermessen gewesen. Das war auch von Anfang an nicht der Plan. Stattdessen wollte ich die Analysen, welche zu den seltsamen Eigenschaften des Manuskripttextes, die ich hier schon einmal thematisiert habe, in einer Umgebung zusammenführen, welche eine einfache Überprüfung der Analyse-Ergebnisse ermöglicht.

Eine aufgeschlagene Seite des Voynich Manuskripts - seltsame Zeichnungen, seltsamer Text. Quelle: en.wikipedia.org
Tatsächlich bin ich aber weiter gekommen, als ich anfangs annahm und wie es dazu kam, will ich hier kurz erzählen: Beim Studium der Literatur zum VMS – die nicht in allen Fällen wissenschaftlichen Ansprüchen genügt und wo sie dies tut, meist in Veröffentlichungen zu anderen Themen versteckt wurde – nahm ich als Grundtenor wahr, dass kein Chiffrierverfahren bekannt wäre, aus dessen Anwendung ein Text resultiert, der dem VMS-Text ähnlich wäre. Ebenso deuteten bestimmte statistische Eigenschaften darauf hin, dass es sich nicht um eine Transkription einer natürlichen Sprache handeln könne. Wenn es aber weder eine Chiffre noch eine unbekannte Transkription sein kann, so liegt die Vermutung nahe, der Text bestehe einfach aus einer sinnlosen Aneinanderreihung von Phantasiewörtern. Damit korrespondiert – semiotisch ausgedrückt – mit der Ausdrucksseite seiner Zeichen keine Inhaltsseite. Und weil ein Text ohne Inhalt auf gewisse Art ein Schwindel ist, wird die Hypothese, dass es sich beim VMS-Text um einen solchen handelt, auch Hoax-Hypothese genannt.
Irgendwie ist der Gedanke, das VMS sei nur ein Schwindel und es gäbe gar nichts zu entziffern, nicht besonders befriedigend. Mehr Charme hat da die Vermutung von William Friedman (einem der größten Kryptoanalytiker des 20. Jahrhunderts), der es für wahrscheinlich hielt, dass der VMS-Text ein früher Entwurf einer synthetischen Sprache a priori sei – ihm also eine Kunstsprache zugrundliege, die sich – im Gegensatz z.B. zum Esperanto – nicht an natürlichen Sprachen orientiert. Weil solche Sprachen aber scheinbar erst in der zweiten Hälfte 17. Jahrhundert entworfen wurden, das VMS aber relativ sicher schon Ende des 16. Jahrhunderts in Prag kursierte, ist diese These problematisch.
Mehr Charme ist jetzt nicht unbedingt ein wissenschaftliches Kriterium. Ich beschloss aber dennoch, Verschlüsselungsverfahren und Ansätze zu Universalsprachen im ausgehenden Mittelalter und der frühen Neuzeit zu recherchieren. Im Zuge dieser Recherchen zu stieß ich auf die Monographie von Gerhard Strasser2 zum Thema, in der dieser die Verbindung zwischen kryptographischen Verfahren und universell gedachten Sprachentwürfen beleuchtet. Ursprünglich wollte Strasser dabei auf die Universalsprachentwürfe des 17. Jahrhunderts eingehen, allgemein als die ersten ihrer Art angesehen. Er kann aber zeigen, dass schon viel früher – durch den Abt Johannes Trithemius (den ich u.a. schon hier für eine andere seiner Arbeiten gewürdigt habe) – eine Chiffre entworfen wurde, deren Anwendung etwas ergab, das wie das Resultat einer Kunstsprache aussieht, das aber ein verschlüsselter Text ist.
Konkret bezieht sich Strasser dabei auf die Teile III und IV der trithemischen Polygraphia. Die darin beschriebenen Verfahren funktionieren prinzipiell wie die aus den ersten beiden Teilen (die ich hier auch schon vorgestellt habe): Einzelne Buchstaben werden gemäß einer Ersetzungstabelle durch ganze Wörter ersetzt. Während aber die Ersetzungschiffren in den ersten beiden Teilen lateinische Wörter sind und die resultierenden Geheimtexte wie lateinische Gebete anmuten, sind sie in den darauffolgenden Büchern von Trithemius erdachte Phantasiewörter, der resultierende Text sieht demnach aus wie eine Phantasiesprache. Der sehr regelmäßige Aufbau der Phantasiewörter – an einen Wortstamm sind unterschiedliche Endungen angehangen – gemahnt Strasser an die Universalsprachentwürfe von Wilkins und Dalgano, die erst viel später, um 1660, entworfen wurden.

Je zwei Zeilen von Ersetzungschiffren aus der Polygraphia III und IV. In der Spalte ganz links finden sich die zu ersetzenden Buchstaben.
Die Tatsache, dass nun doch um 1500 schon eine Möglichkeit beschrieben wurde, wie ein Text erzeugt werden kann, der wie das Produkt einer Kunstsprache aussieht, fesselte mich natürlich und ich beschloss, die Trithemischen Werke im Original zu konsultieren. Die Recherche führte mich in ein Mikrofichekabüffchen und den Lesesaal der historischen Sammlungen der hiesigen Universitätsbibliothek genauso wie in die Erzbischöfliche Buchsammlung zu Köln (womöglich wäre ich noch im Stadtarchiv gelandet, das aber gerade der Erdboden verschluckte) – alles spannende Orte, zu denen man als Computerlinguist unter normalen Umständen gar nicht vorstößt.
Ich werde nie vergessen, wie ich im Holzverschlag zur Mikrofichebetrachtung über das Lesegerät gebeugt stand, fieberhaft und ungelenk die kleine Folie weiterschob über die Tabellen der trithemischen Polygraphia, bis ich endlich im dritten Teil angekommen, überprüfen konnte, ob das, was ich mir auf Grundlage von Strassers Schilderung vorstellte, tatsächlich auch im historischen Werk zu finden war. Und wirklich hatte Trithemius einzelne Spalten mit Stamm-Endungs-Kombinationen versehen, die wie Flexionsparadigmen aussahen (auch die “Wörter” des VMS weisen ähnliche Eigenschaften auf). Noch phantastischer war, dass die manuelle Strichliste, die ich nebenbei über die Wortlängenverteilung der Ersetzungstabellen führte, eine Binomialverteilung ergab (ebenso wie die VMS-”Wörter”, siehe auch hier). Dank Patrick Sahle hatte ich dann bald auch die Möglichkeit, die Polygraphia an meinem Schreibtisch zu studieren, der sich als die langweiligere, aber effektivere Arbeits-Location erwies.
Dort konnte ich mich dann weiteren Überlegungen zur Operationalisierung der von mir ja erst per Augenmaß festgestellten Ähnlichkeiten zwischen den beiden Texten widmen. Dabei hatte ich stets die Warnung von Kennedy und Churchill3 vor Augen, dass das VMS ein Spiegel sei, in dem jeder nur seine eigenen Vorurteile und Hypothesen bestätigt sieht. Insbesondere musste ich erst einmal Werkzeuge entwickeln, die mir erlaubten, den VMS-Text einzulesen und Polygraphia-III-Texte zu erzeugen, diese in Analyseeinheiten zu unterteilen und schließlich statistische Eigenschaften, die ich nicht einfach per manueller Zählung ermitteln konnte, auszuwerten. Ich befand mich erst am Anfang eines langen Prozesses, an dessen Ende die Fertigstellung und Veröffentlichung meiner Dissertation und die der duchgeführten Experimente stand.
Irgendwann später las ich das Bonmot von Ortoli und Witkowski: “Zwischen der Wissenschaft, wie sie die Öffenlichkeit erträumt oder die Medien feiern, und der Wissenschaft, wie sie die Forscher täglich praktizieren, besteht dieselbe Diskrepanz wie zwischen Heldensage und Reisetagebuch.” Da dachte ich, dass - zumindest bei mir im Kopf – genau diese Diskrepanz für einen kurzen Moment aufgehoben war.
1 Katrin Passig, Aleks Scholz: “Lexikon des Unwissens. Worauf es bisher keine Antwort gibt.” Rowohlt Berlin; Auflage: 7 (2007)
2 Gehard Strasser: “Lingua Universalis: Kryptologie und Theorie der Universalsprachen im 16. und 17. Jahrhundert” (Wolfenbütteler Forschungen 38) Harrassowitz, Wiesbaden (1988)
3 Gerry Kennedy und Rob Churchill: “Der Voynich-Code: Das Buch, das niemand lesen kann” Rogner & Bernhard bei Zweitausendeins (2005)
4 Sven Ortoli und Nicolas Witkowski: “Die Badewanne des Archimedes: Berühmte Legenden aus der Wissenschaft” Piper Taschenbuch (2007)
Anm: Drei der vier aufgeführten Bücher sind das, was gemeinhin und bisweilen abschätzig als populärwissenschaftliche Veröffentlichungen bezeichnet wird. Eine ganze Reihe meiner Links führen außerdem zur Wikipedia. Ich halte den Einbezug beider Arten von Quellen für durchaus legitim in einem Blog, der versucht, die eigene wissenschaftliche Tätigkeit etwas populärer zu machen. Dass manche das anders sehen, weiß ich inzwischen auch. Da kann man aber auch gerne mit mir diskutieren. Nebenbei: Untersuchungen zum Voynich Manuskript tragen im Wissenschaftsbetrieb nicht gerade zur Kredibilität bei, was wohl auch ein Grund dafür ist, dass sich so wenige wirkliche Spezialisten mit dem Thema beschäftigen oder aber ihre Ergebnisse in Unterkapiteln anderer Veröffentlichungen (z.B. in einer Einführung in die Programmiersprache BASIC, kein Witz) verstecken. Bei mir ist das ja auch irgendwie der Fall gewesen. 
Quelle: http://texperimentales.hypotheses.org/278