Die Theologie und Religionswissenschaft verbindet eine lange (Fach-)Geschichte, die bis heute – zumindest in Teilen – von Missverständnissen, gegenseitigen Vorwürfen und offensiv vorgetragenen Abgrenzungsversuchen geprägt ist.Aus der Sicht eines Religionswissenschaftlers bzw. einer Religionswissenschaftlerin würden die beiden Disziplinen idealiter wie folgt unterschieden: die Theologie beschäftigt sich aus einer Innenperspektive mit Religion und behandelt dabei, neben vielen anderen Bereichen, auch spezifische Fragen, die nur für Anhänger/-innen der jeweiligen Religion Sinn ergeben, wozu bspw. Glaubensfragen (Dogmatik) oder Fragen der Auslegung der jeweils relevanten Schriften (Exegese) gehören. Die Religionswissenschaft im Unterschied zur Theologie beschäftigt sich hingegen nicht mit dem Wahrheitsgehalt von spezifischen Glaubensvorstellungen (ein Bereich, welcher der Theologie vorbehalten ist) oder von Religion(en) insgesamt (dies wird meist als methodischer Agnostizismus bezeichnet), sondern nimmt eine Außenperspektive ein, indem sie Religionen als gesellschaftliche Phänomene analysiert (z.B. aus soziologischer, psychologischer, philologischer oder historischer Perspektive). Dass die hier angeführte Trennung zwischen Theologie und Religionswissenschaft bis heute problematisch ist und nicht immer stringent eingehalten wird (und zwar von beiden Seiten), zeigen nicht nur theologisch orientierte religionswissenschaftliche Forschung (bspw. in Form der konfessionell ungebundenen Suche nach „der wahren Religion“ oder „der Wahrheit in den Religionen“), sondern auch das Gegenteil, nämlich die dezidierte Kritik an Religion(en) (siehe z.B.
[...]
Was ich beim Geschichtstalk gelernt habe
Rund um die Premiere des Geschichtstalks herrschten Aufregung und Durcheinander im Super7000. Wie es in einem improvisierten Fernsehstudio voller Historiker_innen wirklich zugeht, wenn Funken sprühen und ein groß angekündigter Livestream bevorsteht, das soll jedoch ein andermal erzählt werden. Heute geht es mir um die Argumente, die in der Talkrunde aufeinander prallten, und denen ich während der Livesendung kaum folgen konnte. Die meisten haben wahrscheinlich nicht einmal gemerkt, dass da Argumente aufeinander prallten, so einig wollten sich die Talker_innen vor der Kamera sein. Zu viel … „Was ich beim Geschichtstalk gelernt habe“ weiterlesen
DH-Kolloquium I – Onkel Rick erzählt vom Krieg
“Wie stehst du zu den Digital Humanities?” ist eine Frage geworden, um die man als Geisteswissenschaftler, vor allem als einer, der irgendwie auch mit der Erstellung und Nutzung von Software zu tun hat, nicht mehr herumkommt.
Von außen mag es ja so aussehen, als wenn ich zwangsläufig DHer bin, schließlich bin ich mit für einen Studiengang verantwortlich, der als einer der ersten tatsächlich ein DH-Curriculum anbot (auch wenn “Informationsverarbeitung” draufsteht) – und stellvertretender Sprecher eines Zentrums, welches die DH in Köln vertritt (auch wenn es Cologne Center for e-Humanities / CCeH heißt). Dazu sind die beiden den Studiengang Informationsverarbeitung in Zukunft tragenden Lehrstühle momentan neu explizit als DH-Professuren ausgeschrieben. Zeit also, um darüber nachzudenken, meinen Status als Computerlinguist zu überdenken und mich als DHer neu zu erfinden?
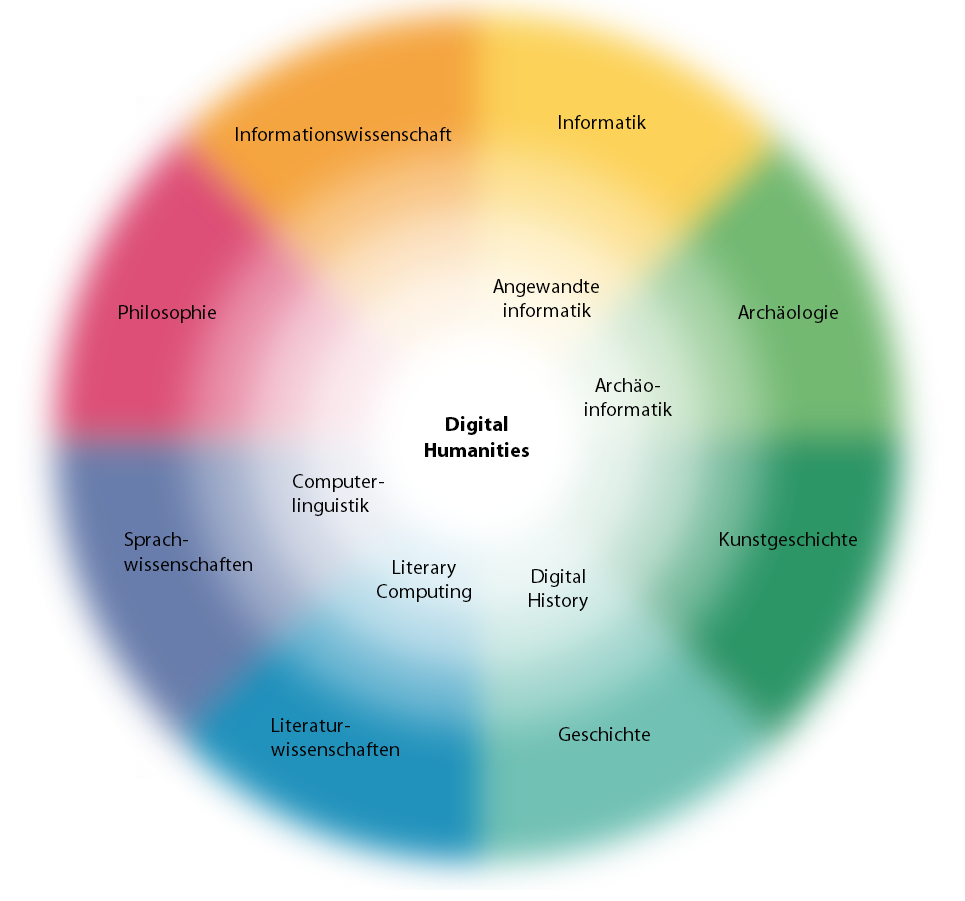
Einzelwissenschaften und ihre Ausrichtung auf die Digital Humanities. Oder umgekehrt? (aus Sahle 2013)1
Durch meine (mir irgendwie zugefallene Funktion) im CCeH erhielt ich tatsächlich einmal einen Einblick in die Arbeitswelt von Wissenschaftler|inne|n jenseits der maschinellen Analyse von Textdaten. Und konnte auf der anderen Seite dort Ideen in Forschungsanträgen unterbringen, die eher aus dem von mir gemeinhin bearbeiteten Bereich stammen. Alles in allem entwickelte sich ein durchaus fruchtbarer Austausch, den die Beteiligten weiter verfestigen wollten – was liegt da an einer Uni näher als eine gemeinsame Lehrveranstaltung? Also startete ich mit Patrick Sahle (Geschäftsführer des CCeH), Franz Fischer (Projektmanager DiXiT) und Claes Neuefeind (Mitarbeiter am Lehrstuhl für Sprachliche Informationsverarbeitung, wie ich) die Planung für ein gemeinsames Kolloquium, das wir nutzen wollen, uns gegenseitig, aber auch interessierten Studierenden Einblick in unser Verständnis von DH zu geben.
Den Anfang machte gestern mein geschätzter und im DH-Umfeld weithin bekannter Kollege Patrick Sahle, indem er die Frage aufwarf, was denn die Digital Humanities überhaupt seien. Als (noch, gefühlter) DH-periphärer Wissenschaftler scheint mir diese Frage innerhalb diese Forschungszweiges die meistdiskutierte überhaupt zu sein. Wahrscheinlich gilt aber für alle Forschungsfelder, die im Begriff sind, ein Fach (also quasi institutionalisiert) zu werden, dass sie zunächst einen langen Kampf gegen bestehende Strukturen führen müssen, ehe sie selbst als eine etablierte anerkannt werden. Auf dem wissenschaftlichen Schlachtfeld geht es natürlich oft einfach um die Verteidigung von Pfründen – Planstellen, Fördergelder, Deutungshoheit. Um sich da durchzusetzen, muss man als Unterstützer|in einer neuen Fachrichtung lange, zähe Kämpfe bestehen und sich durchzusetzen wissen.
Patrick führte nun ein paar Belege dafür an, dass die Institutionalisierung der DH (deren Definition nicht so ganz scharf gefasst werden kann – hier findet man aber mehr als 800 Versuche, das zu tun) schon relativ weit fortgeschritten ist und uns möglicherweise auch erhalten bleiben wird. Zu diesen Belegen zählen die Organisationsstruktur in weltweite, kontinentale, ländereigene und lokale DH-Verbände, die Ausbildung von Zentren (wie z.B. dem Kölner CCeH), eine Vielzahl von Tagungen und Zeitschriften zum Thema sowie – noch recht spärlich gesät, aber immerhin schon vorhanden – DH-Studiengänge, wie wir in Köln eben auch einen haben.2

Sind DH eine Schnittmenge oder die Klammer zwischen zwei Schnittmengen? (aus Sahle 2013)
Relativ unstrittig ist die Frage, dass es eine Schnittmenge zwischen den einzelnen Geisteswissenschaften und der Informatik gibt und das man diese als Digital Humanities bezeichnen kann. Die Frage ist allerdings, ob die DH vollständig in dieser Schnittmenge aufgehen oder ob es einen wesenhaften DH-Kern gibt, der weder Fachwissenschaft noch Informatik ist. Patrick ist der Meinung, dass sich dort tatsächlich etwas befindet, und da kann ich tatsächlich zustimmen. Was sich aber genau da befindet, darüber kriegen wir uns gegenwärtig sicher noch in die Haare, so wie wir das bezüglich unser unterschiedlichen Textbegriffe spaßeshalber fast immer tun, wenn wir uns sehen. Das Scharmützel bezüglich Text versuchen wir in der nächsten Sitzung des Kolloquiums im Boxring zu klären. Wenn es mein Zustand danach erlaubt, werde ich berichten. ![]()
1 Beide Grafiken sind mir dankenswerterweise von Patrick zur Verfügung gestellt worden – und zwar ohne dass er wusste, was ich hier denn so schreibe. Sie sind entnommen aus: Patrick Sahle (2013): “DH Studieren! Auf dem Weg zu einem Kern- und Referenzcurriculum der Digital Humanities“. DARIAH-DE Working Papers Nr. 1. Göttingen: DARIAH-DE, 2013. URN: urn:nbn:de:gbv:7-dariah-2013-1-5
2 Patrick erwähnte auch DH-Blogs, die aber seiner Meinung nach oft zu bloßen Pressemitteilungs-Veröffentlichungs-Plattformen verkommen wären – diese Bemerkung ist nicht ganz unschuldig daran, dass ich mich heute hier an den Beitrag gesetzt habe.
aventinus collectanea [31.03.2015]: Andreas C. Hofmann: Studieren und Publizieren. Beiträge aus Theorie und Praxis zu einer modernen Form von Wissenschaftskommunikation
https://www.aventinus-online.de/collectanea Die Schriftensammlung bietet einen Überblick zum Œuvre des Geschäftsführenden Herausgebers zu Studentischem Publizieren. Die Abschnitte Theorie und Praxis vereinen hierbei seine theoretisch-deskriptiven Erörterungen mit Beiträgen aus der Studienzeit.
aventinus academica Nr. 6 [13.04.2014]: Wissenschaftstheoretisches ‚Nachwort‘ zur Dissertation von Andreas C. Hofmann
In seiner Februar 2014 von der LMU München abgenommenen geschichtswissenschaftlichen Dissertation verfasste Geschäftsführender Herausgeber Andreas C. Hofmann ein wissenschaftstheoretisches Nachwort zu neuen Formen von Wissenschaftskommunikation wie Studentischem Publizieren. http://bit.ly/Q3JkXK
Geisteswissenschaftler, wo sind Eure Antworten? Max Weber Stiftung und Gerda Henkel Stiftung eröffnen eine gemeinsame Internetreihe zur Zukunft der Geisteswissenschaften
http://mws.hypotheses.org http://www.lisa.gerda-henkel-stiftung.de Wie präsent sind die Geisteswissenschaften in der Öffentlichkeit? Welche Deutungshoheit haben sie? Und wie bleiben die Geisteswissenschaften angesichts der digitalen Veränderungen zukunftsfähig? Die Max Weber Stiftung – Geisteswissenschaftliche Institute im Ausland und die Gerda Henkel Stiftung starten heute das gemeinsame Internetformat „Max meets Lisa“. Hier sprechen Geschichts-, Sozial- und Kulturwissenschaftlerinnen und -wissenschaftler über [...]
Geisteswissenschaftler, wo sind Eure Antworten? Max Weber Stiftung und Gerda Henkel Stiftung eröffnen eine gemeinsame Internetreihe zur Zukunft der Geisteswissenschaften
http://mws.hypotheses.org http://www.lisa.gerda-henkel-stiftung.de Wie präsent sind die Geisteswissenschaften in der Öffentlichkeit? Welche Deutungshoheit haben sie? Und wie bleiben die Geisteswissenschaften angesichts der digitalen Veränderungen zukunftsfähig? Die Max Weber Stiftung – Geisteswissenschaftliche Institute im Ausland und die Gerda Henkel Stiftung starten heute das gemeinsame Internetformat „Max meets Lisa“. Hier sprechen Geschichts-, Sozial- und Kulturwissenschaftlerinnen und -wissenschaftler über […]
Gegenworte. Hefte für den Disput über Wissen Nr. 29 (Frühjahr 2013): Skandalisierung (in) der Wissenschaft
http://www.gegenworte.org/heft-29/gegenworteheft29.html Sei’s als Skandalisierung von Regelverstößen, sei’s als Strategie zur Erregung öffentlicher Aufmerksamkeit: Hier zeigt sich auch immer ein Kampf um Normen, Macht und Einfluss, um Deutungshoheit und Interpretationsvorherrschaft. Wer bestimmt, was skandalisierungsfähig ist? Vom Anspruch her sind Skandalisierungen in der Wissenschaft höchst fehl am Platz, denn hier sollten das bessere Argument zählen, die sachliche […]
aventinus generalia Nr. 16 [17.12.2012]: Wissenschaftstheorie, Wissenschaftspolitik und die Gründung eines “Instituts für Studentisches Publizieren” — einige Überlegungen [=L.I.S.A. (Jan. 2013)]
https://www.aventinus-online.de/index.php?id=3800 Im Preprint eines bei “L.I.S.A. Das Wissenschaftsportal der Gerda-Henkel-Stiftung” erscheinenden Artikels rekurriert der Geschäftsführende Herausgeber Andreas C. Hofmann über wissenschaftstheoretische, wissenschaftspolitische sowie institutionelle Aspekte Studentischen Publizierens.
Scheitern als Chance – Testen durch Fehler
Momentan experimentiere ich mit Marcos Zampieri zu Eigenschaften von brasilianisch-portugiesischen Internettexten. Dabei geht es unter anderem darum, spezifisches Vokabular aus diesen zu extrahieren und anhand dieses Vokabulars die Texte wiederum nach ihrer Internetness zu klassifizieren. Die Studie erscheint demnächst als Paper, hier will ich deswegen nicht über die Ergebnisse schreiben, sondern nur eine (zumindest für uns) lehrreiche Begebenheit aus der Entwicklungsphase schildern.
Aus wissenschaftlichen Veröffentlichungen lässt sich nur in den seltensten Fällen herauslesen, welche Fehlschläge auf dem Weg zu den letztlich öffentlich gemachten Versuchsaufbauten und Ergebnissen die Autoren hinnehmen mussten. Um zu zeigen, dass solche Fehlschläge durchaus fruchtbar sein können, muss ich zunächst etwas weiter ausholen und bei den drei Gütekriterien empirischer Studien beginnen, die ja, wie allgemein bekannt, die folgenden sind:
- Validität – Misst das gewählte Verfahren tatsächlich das, was es messen soll?
- Reliabilität – Funktioniert die Messung zuverlässig, sind die Ergebnisse im Wiederholungsfall stabil?
- Objektivität – Wurden die Ergebnisse unabhängig vom Prüfer erzielt?
Auch wenn man – wie wir – ein Labor gebaut hat, in dem alles, was man experimentell anstellt, protokolliert wird, so dass die Ergebnisse im Normalfall (d.h., wenn man die Ausgangsdaten und die Werkzeuge in den entsprechenden Versionen nicht verlegt) jederzeit reproduziert werden können, sind diese drei Kriterien natürlich nicht automatisch erfüllt.
Wir (Computer)Linguisten wollen z.B. Aussagen über Sprache treffen und analysieren dafür Sprachdaten. Diese Aussagen sind natürlich immer abhängig von der Auswahl der Sprachdaten, die wir getroffen haben. Natürliche Sprachen sind ja leider kein abgeschlossenes System (im Gegensatz z.B. zum Text aus dem Voynich Manuskript, jedenfalls solange dessen fehlende Seiten nicht irgendwo auftauchen). Die Auswahl betrifft vor allem die beiden letzten oben genannten Gütekriterien, die Reliabilität (bleiben die Aussagen gleich, wenn ich eine andere Auswahl treffe) und Objektivität (bleiben die Aussagen gleich, auch wenn jemand anders die Auswahl trifft).
Die Validität betrifft mehr die Werkzeuge, die im Analyseprozess verwendet werden – zunächst einmal müssen sie korrekt funktionieren (wer selbst einmal Algorithmen implementiert hat, weiß wahrscheinlich sehr gut, welche Fehler dabei auftreten können). Darüber hinaus muss aber auch irgendwie festgestellt werden, ob sich die Messungen der gewählten Werkzeuge wirklich dazu eignen, darauf die zu treffenden Aussagen zu gründen.
Im kombinierten Programmier/Experimentier-Prozess, in dem man sich befindet, wenn man neue Werkzeuge erstellt, die dann auch umgehend für empirische Studien eingesetzt werden, muss man sich überlegen, wie man die Validität denn am besten testen kann. Und um jetzt endlich zum Punkt dieses Artikels zu kommen: Ich möchte hier einen solchen Test beschreiben, der in der Form gar nicht geplant war und nur durch einen Fehler zustande kam.
Um, wie wir das vorhatten, die Internetness von Texten bzw. Dokumenten zu ermitteln, kann man sie z.B. mit einem Referenzkorpus vergleichen und schauen, inwieweit sich Spezifika in Abgrenzung zu diesem ermitteln lassen. Es gibt unterschiedliche Methoden, die Keywordness von einzelnen Termen (Wörtern) zu berechnen, im Bereich des Information Retrieval (also im Umfeld von Suchmaschinen) wird häufig der Quotient aus Termfrequenz und inverser Dokumentfrequenz (TF/IDF) hinzugezogen. Für den Vergleich von Korpora eignet sich unserer Meinung nach die Berechnung der Log-Likelihood-Ratio (LLR) für einzelne Termes besser. Um es ganz simpel zu erklären: Das Vorzeichen der LLR gibt für jeden Term an, ob er stärker mit dem Untersuchungskorpus oder mit dem Referenzkorpus assoziiert ist. Noch einfacher: In welchem Korpus er häufiger vorkommt. Allerdings zählen dabei nicht die absoluten Häufigkeitsunterschiede (welche die frequentesten Wörter, also {und, der, die, das} usw. aufweisen würden), die LLR relativiert diese stattdessen (wie sie das tut, passt gerade nicht hier rein). Summiert man nun die LLR-Werte der Token jedes Korpus-Dokumentes und teilt diese Summe durch die Länge des entsprechenden Dokuments, so erhält man vergleichbare Internetness-Werte für jedes Dokument.

Ein Experiment, das den im Text beschriebenen Workflow über einzelne Komponenten realisiert. Von oben nach unten: Korpora, Tokenizer, Frequenz-Zähler, LLR-Berechner, Ranker für Dokumente (die hier in Paragraphen repräsentiert sind) nach den LLR-Werten ihres Vokabulars.
Auf den ersten Blick war fatal, dass uns der Fehler unterlief, unsere Korpora mit Texten unterschiedlicher Encodings zu bestücken. Das ist für Tesla normalerweise kein Problem, wenn nicht gerade alle zusammen in einem Archiv hochgeladen werden, was wir aber getan haben. Das Resultat war, dass alle Wörter mit Umlauten im Internet-Korpus korrekt dargestellt wurden, diese aber im Referenz-Korpus nie auftauchten, weil dessen Encoding zerschossen war. Resultat war, dass não (portugiesisch für nein, falsch encodiert não), offenbar in unserem Korpus das frequenteste Wort mit Sonderzeichen, den höchsten LLR-Wert erhielt. Texte, die lediglich aus não bestanden, bekamen deshalb den höchsten Wert für ihre Internetness.
Das Ergebnis entsprach natürlich keinesfalls dem, das wir erhalten wollten, dennoch hatte die Tatsache, dass wir einen so blöden Fehler gemacht hatten, auch einen gewichtigen Vorteil: Dadurch, dass wir ein so falsches, aber absolut nachvollziehbares Ergebnis erhielten, konnten wir Rückschlüsse bezüglich der Validität des Verfahrens bzw. die Richtigkeit der Algorithmen-Implementationen innerhalb der Komponenten ziehen: Wir hatten genau das gemessen, was aufgrund unseres Fehlers gemessen werden musste. Den Fehler konnten wir einfach korrigieren, die Ergebnisse veränderten sich dementsprechend – auch wenn sie weiterhin bemerkenswerte, durch die Korporaauswahl bedingte, Artefakte enthalten (da muss ich allerdings auf die wissenschaftliche Veröffentlichung vertrösten). Wir waren in einem ersten Versuch gescheitert, aber gerade dieses Scheitern hatte uns einen relativ starken Hinweis auf die Validität unseres Verfahrens gegeben. Und ich finde, das ist schon einen Blogpost wert, zumal solche produktiven Fehlschläge nur sehr selten Platz in wissenschaftlichen Veröffentlichungen finden.