Ein Beitrag von Simone Brehmer, Jonas Feike, Jana Lörcher, Lars Schlaphof, Sabrina Stünkel...
Das Deutsche Textarchiv in der Graphenwelt
Einleitung Das Deutsche Textarchiv (DTA) stellt einen Disziplinen übergreifenden Grundbestand deutscher Werke aus dem Zeitraum von ca. 1600 bis 1900 im Volltext und als digitale Faksimiles frei zur Verfügung und bereitet ihn so auf, dass er über das Internet in…
Graphbasierte digitale Editionen
Das Problem Bei digitalen Editionen in den Geisteswissenschaften ist XML heute ein Standard. Oft wird TEI-XML für die Auszeichung literarischer und historischer Quellen verwendet. Wenn nun in einem Dokument multiple Hierarchien ausgezeichnet werden sollen, ergeben sich Probleme. Hierzu gehört die…
Graphdatenbanken für Historiker. Netzwerke in den Registern der Regesten Kaiser Friedrichs III. mit neo4j und Gephi
Digitale Farbenspiele oder nützliches Werkzeug – Visualisierung von Netzwerken aus den Registern von Editions- und Regestenwerken
Abstract
Im Rahmen der Big-Data-Welle wird sehr interessante kommerzielle aber auch Open-Source Software zur Analyse von großen Datenmengen entwickelt. In diesem Beitrag wird beispielhaft die Open-Source-Visualisierungssoftware Gehpi zur Visualisierung von Netzwerkstrukturen im Personenregister eines Urkundenbuchs verwendet. Prinzipiell ist dieser Ansatz auf weitere Editions- und Regestenwerke übertragbar. Damit könnten die in den Registern abgelegten Informationen über den traditionellen Zugriff hinaus für einen neuen Blick auf das Quellenmaterial nutzbar gemacht werden.
Inhaltsverzeichnis
1 Am Anfang standen Youtube und Facebook
2 Das kumulierte Register der Regesten Kaiser Friedrichs III.
2.1 Die Idee zur Visualisierung von Registerinformationen
2.2 Die Qualität der Netzwerkdaten
2.3 Das Verweissystem des Registers
3.1 Das Personenregister im Arnsburger Urkundenbuch
4 Visualisierung des Registers mit Gephi
4.1 Umwandlung der Daten in gexf-Format
4.2 Öffnen der gexf-Datei in Gehpi
4.4 Auswahl des Layout: ForceAtlas2
1 Am Anfang standen Youtube und Facebook
Anfang des Jahres 2014 stöberte ich an einem Wochenende auf Youtube nach Visualisierungsmöglichkeiten für Netzwerkstrukturen. Dabei stieß ich auf ein Videotutorial[1] des Youtube-Nutzers spaetzletube[2], in welchem dieser die Visualisierung der Netzwerke seines Facebook-Accounts mit der Opensource-Software Gephi[3] vorstellte.

Abbildung 1: Youtube-Video von Spaetzletube
Die Präsentation war sehr gut strukturiert und weckte mein Interesse. Leider besitze ich selbst keinen Facebook-Account um die Visualisierungsmöglichkeiten an eigenen Daten auszuprobieren und fragte eine Kollegin, ob Sie mir nicht ihre Facebookdaten zur Verfügung stellen könnte. Sie war einverstanden und wir analysierten ihre persönlichen Facebooknetzwerke.

Abbildung 2: Das visualisierte Facebooknetzwerk meiner Kollegin
Die Ergebnisse waren überraschend klar, man konnte verschiedene Cluster klar voneinander trennen, wie privater Freundeskreis, Kontakte an der Arbeit und Kontakte aus dem Sport.
2 Das kumulierte Register der Regesten Kaiser Friedrichs III.
Gleichzeitig war ich im Rahmen meiner Arbeit bei den Regesta Imperii gerade an der Vorbereitung der Internetbereitstellung der kumulierten Register der Regesten Kaiser Friedrichs III. beteiligt.
2.1 Die Idee zur Visualisierung von Registerinformationen
Während meiner Arbeiten am Register kam ich auf eine Idee:
Wäre es nicht denkbar, für zwei Personen, die gemeinsam in einem Regest genannt werden, eine Verbindung zu postulieren. Diese Verbindung ist zwar qualitativ schwach aber doch vorhanden und ergibt sich aus den Angaben im Register. Spielt man diesen Gedanken für das gesamte Register durch, müsste sich eine große Zahl von 1zu1-Beziehungen ergeben, wobei jede Beziehung gleichzeitig mit einem Datum und einer Ortsangabe versehen ist, da sie die gemeinsame Nennung in einem Regest repräsentiert und dieses Regest hat in der Regel ein Datum und einen Ausstellungsort.
Wenn es also gelingen könnte, alle gemeinsamen Nennungen, die sich aus den Angaben in einem Register ergeben computerlesbar aufzubereiten, sollte eine Visualisierung dieser Verknüpfungen analog zu o.a. Facebook-Beispiel möglich sein.

Abbildung 3: Die sich aus den Registerangaben ergebenden Beziehungen der in einem Regest genannten Personen
Zur Illustration der Idee werden in der Abb. beispielhaft die sich aus Regest Nr. 189 des Heftes 19 der Regesten Kaiser Friedrichs III. ergebenden Bieziehungen dargestellt. So sind in dem Regest mehrere Mitglieder der Familie Volckamer genannt, von denen Stephan Volckammer als Lehensträger bestätigt wird. Anwesend war auch Werner von Parsberg, Schultheiß zu Nürnberg. Ulrich Waeltzli, Mitarbeiter in der Kanzlei Friedrichs III., wird im Kanzleivermerk genannt und steht daher auf qualitativ gleicher Ebene wie die oben genannten Personen mit dem Regest in Verbindung. Und hier ist ein erster Hinweis in Hinblick auf die Qualität der Daten nötig.
2.2 Die Qualität der Netzwerkdaten
Man kann mit einiger Wahrscheinlichkeit davon ausgehen, dass sowohl die Mitglieder der Familie Volckamer als auch Werner von Parsberg in den regestierten Vorgang eingebunden und möglicherweise auch vor Ort waren. Der im Kanzleivermerk genannte Ulrich Waelzli war dagegen mit hoher Wahrscheinlichkeit nicht zugegen[4], würde aber trotzdem in gleicher Weise mit dem Regest in Verbindung gebracht, wie die anderen genannten Personen auch.
Zieht man daher Schlüsse aus der Visualisierung, muss man sich immer bewusst sein, dass die Qualität der Verknüpfungen im Netzwerk schwach ist. Im Gegensatz zu Auswertungen von Daten sozialer Netzwerke haben wir keine ergänzenden persönlichen Informationen, welche die Verknüpfungen weiter gewichten könnten. Andererseits liegen aber sehr viele Verknüpfungsdaten vor, was wiederum trotzdem interessante Aussagen ermöglichen sollte.
2.3 Das Verweissystem des Registers
Eine zweite wichtige Einschränkung ergibt sich aus der Art der Verweise im Register. Für die Analyse von Netzwerken können nur Register verwendet werden, die auf Urkundennummern, Regestennummern oder ähnliches verweisen, also auf Sinneinheiten. Wird dagegen auf Seitenzahlen verwiesen, ist nicht sichergestellt, dass die Verweise sich auf die gleiche Sinneinheit beziehen.
Am Ende der Analyse des Regests und der ihm zuordneten Registereinträge steht eine Liste von 1zu1-Beziehungen, die mit Netzwerkvisualisierungssoftware wie z.B. Gephi visualisiert werden kann.
3 Ein Beispiel

Abbildung 4: Arnsburger Urkundenbuch
3.1 Das Personenregister im Arnsburger Urkundenbuch
Die im vorherigen Abschnitt vorgestellte Idee diskutierte ich im folgenden mit vielen Kolleginnen und Kollegen und die meisten fanden den Ansatz sehr interessant, aber leider fand sich keiner, der ihn an einem Beispiel hätte umsetzen können. Daher fasste ich den Entschluss, die Idee selbst modellhaft an einem überschaubaren Datenbestand auszuprobieren. Meine Wahl fiel auf das Register des vom Darmstädter Archivar Ludwig Baur bearbeiteten Urkundenbuchs des Klosters Arnsburg in der Wetterau[5], welches Mitte des 19. Jahrhunderts in drei Teilbänden erschienen ist. Das Urkundenbuch enthält im dritten Teil ein Personen- und ein Ortsregister, wobei hier nur das Personenregister verwendet wurde, da es vor allem um Personennetzwerke gehen soll. Als Scan wurde die Version von Google-Books verwendet, deren Bildqualität für die Retrodigitalisierung ausreichend schien.

Abbildung 5: Ausschnitt aus dem Personenregister des Arnsburger Urkundenbuches
Im ersten Schritt wurde die PDF-Version des Registers mit Hilfe der OCR-Software Abby-Finereader in eine Textdatei umgewandelt und anschließend nachbearbeitet und korrigiert, bis dann schließlich eine Textdatei des Registers zur Verfügung stand, die vom Layout her dem Original entsprach.

Abbildung 6: Ausschnitt aus dem Ergebnis der Digitalisierung des Registers mit Finereader
3.2 Vom Text zur Tabelle
Mit Hilfe eines Kollegen[6] gelang es, den Volltext des digitalisierten Registers in eine strukturierte Form zu bringen, die dann die Weiterverarbeitung in eine Tabelle ermöglichte.

Abbildung 7: Strukturierte Textdaten des Registers (beispielhafter Ausschitt)

Abbildung 8: Das digitalisierte Register des Urkundenbuchs im Tabellenformat
In der Tabelle wird beispielhaft der Abschnitt des Registers um den Eintrag des Ritters Cuno Colbendensel aus Bellersheim und seiner Frau Alheid gezeigt. Es ist zu erkennen, dass zu jeder Urkundennummer im Register eine Tabellenzeile erstellt wurde. Jede Tabellenzeile in dieser Datei repräsentiert also die Nennung einer Person in einer Urkunde des Urkundenbuchs.

Abbildung 9: Schaubild zur Erstellung der Tabellenform des Registers aus den Einträgen in der gedruckten Fassung
Die Darstellung der Registerinformationen in Tabellenform erlaubt es durch Sortierung nach Urkundennummern in kürzester Zeit, alle in einer Urkunde genannten Personen aufzulisten.

Abbildung 10: Nach Sortierung der Urkundennummern erhält man alle in der Urkunden 796 vorkommenden Personen.
In der Abbildung werden nach Sortierung der Urkundennummern alle in Urkunde 796 im Register genannten Personen sichtbar. Selbstverständlich könnte man mit dem Durchlesen der Urkunden zum gleichen Ergebnis kommen, ggf. hätte man sogar einen besseren Überblick zu den Inhalten von Urkunde 796. Der Vorteil der Tabellenform ist aber, dass sie computerlesbar ist und mit entsprechenden Programmen alle Verknüpfungen gemeinsam sichtbar gemacht werden können.
Mit der Tabelle liegen nun die notwendigen Informationen des Registers computerlesbar vor.
4 Visualisierung des Registers mit Gephi
4.1 Umwandlung der Daten in gexf-Format
Vor der Visualisierung des Registers mit Gephi müssen die Daten noch in das Gephi-xml-Format gexf[7] umgewandelt werden[8]. Zunächst wird hierfür eine Liste aller im Register vorkommenden Personen erstellt. Sie finden sich im ersten Teil der xml-Datei. Die Einträge zu den einzelnen Personen werden in Gephi als nodes bezeichnet.

Abbildung 11: Liste aller im Register vorkommenden Einträge, in Gephi als nodes bezeichnet.
Im zweiten Abschnitt der Datei befinden sich dann alle Verbindungen (edges) zwischen Personen (nodes), die sich aus der gemeinsamen Nennung in einer Urkunde ergeben.

Abbildung 12: Abschnitt der XML-Datei, in der die Edges festgelegt werden
In der Abbildung wird beispielsweise eine Verbindung zwischen der Person (node) mit der ID 16 und der Person (node) mit der ID 95 hergestellt. Hinzu kommen noch Angaben zum Ort (Dreise …) und zum Datum (1198-01-01), die sich jeweils aus den Angaben der Urkunde ergeben[9].
4.2 Öffnen der gexf-Datei in Gehpi
Nach der Installation von Gephi können Sie die Datei nun öffnen. Die Präsentation mit Gephi habe ich auch auf Youtube als Video-Tutorial abgelegt:
Die Software Gephi ist Open-Source und unter
für die Betriebssysteme Windows, MacOS und Linux erhältlich[10].

Abbildung 13: Gephi nach dem Öffnen der gexf-Datei. In der Mitte die noch unbearbeitete Visualisierung des Registernetzwerkes

Abbildung 14: Ansicht auf einen Ausschnitt des Punktequadrats. Jeder Punkt symbolisiert jeweils ein Lemma aus dem Register, jede Linie jeweils eine gemeinsame Nennung von zwei Lemmata in einer Urkunde.
Nach dem Öffnen in Gephi sieht man im mittleren Fenster ein Quadrat, das zunächst die Visualisierung unseres Registernetzwerkes darstellt.
Zoomt man mit dem Mausrad in das Quadrat[11], werden die einzelnen Punkte mit den Verküpfungen sichtbar. Jeder Punkt (Node) symbolisiert jeweils ein Lemma aus dem Register, jede Linie (Edge) jeweils eine gemeinsame Nennung von zwei Lemmata in einer Urkunde.
4.3 Das Data Laboratory
Wählt man im oberen Bereich des Programmfensters den Reiter Data Laboratory aus, erscheinen die der Netzwerkvisualisierung zu Grunde liegenden Daten. Unter Nodes erkennen wir unsere Personen aus dem Register wieder. Den ersten Eintrag mit der ID 0 bildet z.B. Wigand von Aslar.

Abbildung 15: Das Data Laboratory bietet in Gephi Zugriff auf die Datengrundlage. Hier werden die Nodes angezeigt.
Unter dem Reiter Edges werden die Verknüpfungdaten (Edges) angezeigt. Der erste Edge verweist auf eine gemeinsame Nennung von Wigand von Aslar (mit der ID 0) und Adelheid, der Witwe des Ritters Johann von Schelm (mit der ID 2), der zweite Eintrag verweist auch von Wigand von Aslar auf einen Wigand mit der ID 1456 usw. Im Datenlabor hat man also Zugriff auf alle der Visualisierung zu Grunde liegenden Daten.

Abbildung 16: Unter Edges werden alle Verküpfungen zwischen den Nodes aufgelistet.

Abbildung 17: Die Nodes und Edges nach der Anwendung des Layouts ForceAtlas2.
4.4 Auswahl des Layout: ForceAtlas2
Kehren wir zum Quadrat zurück, der nun bearbeitet werden soll. Auf der linken Seite des Programmfensters können im Fenster Layout verschiedene Layouts für die weitere Bearbeitung der Daten ausgewählt werden. In unserem Beispiel wenden wir nun das Layout ForceAtlas2 an. Nach kurzer Zeit hat sich unser Quadrat auseinandergezogen und es werden verschiedene Zentren bzw. Gruppen von Nodes sichtbar. In den folgenden Abschnitten werden noch weitere Funktionen erläutert, mit denen charakteristische Merkmale der Daten sichtbar gemacht werden können.
4.5 Modularity

Abbildung 18: Mit der Funktion Modularity farbig markierte Gruppen im Netzwerk.
Die verschiedenen Gruppen des Netzwerks lassen sich mit weiteren Funktionen aus der Cluster Analyse besser sichtbar machen. Hierfür wählt man am rechten Rand unter Statistics die Funktion Modularity aus, mit der dann die einzelnen Gruppen farbig gekennzeichnet werden.
4.6 Degree Range
Unter dem Reiter Filters am rechten Bildrand gibt es noch weitere Analysemöglichkeiten. Unter dem Punkt Topology befindet sich der Unterpunkt Degree Range. Mit diesem kann man auswählen, wieviele Verknüpfungen eine Node haben muss, damit sie noch angezeigt wird. Für unser Beispiel haben wir die alle Nodes ausgeblendet, die 42 oder weniger Verknüpfungen haben.
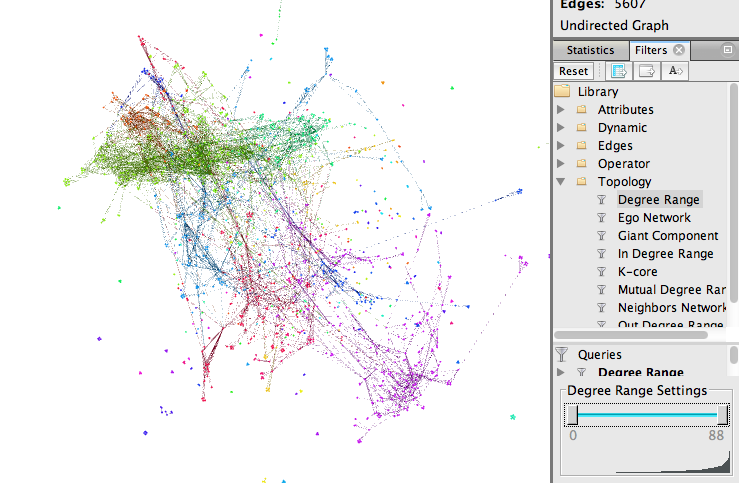
Abbildung 19: Netzwerk ohne Filter.

Abbildung 20: Netzwerk mit Degree-Range-Filter.
In der oberen Abbildung (Abb. 19) wird das gesamte Netzwerk abgebildet, im unteren Bild (Abb. 20) nur noch jene Nodes, die 43 oder mehr Verknüpfungen haben. Zu diesen „wichtigen“ Nodes lassen sich auch die Namen einblenden.
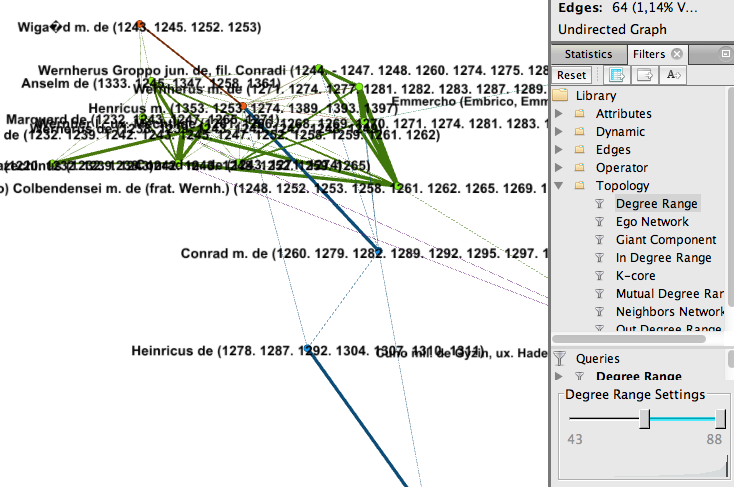
Abbildung 21: Eingeblendete Namen der gefilterten Nodes.
Wechselt man von dieser Ansicht ins Datenlabor, werden dort nur noch jene Nodes angezeigt, die in der Auswahl vorher sichtbar waren.

Abbildung 22: Blick ins Datenlabor. Hier werden nur noch jene Nodes angezeigt, die vorher in der Auwahl sichtbar waren.
4.7 Timeline
Abschließend soll noch die Verwendung der Timeline in Gephi erläutert werden. Die Datengrundlage unserer Visualisierung bilden zum einen die aus dem Register extrahierten Personen (Nodes) und die aus den Urkundenangaben im Register gewonnen Verküpfungen (Edges). Jede Verküpfung zwischen zwei Personen geht also auf die gemeinsame Zuordnung zu einer Urkunde zurück. Die Urkunde selbst hat in der Regel einen Ausstellungsort und ein Datum. Genau diese Angaben kann man den Verknüpfungen zuordnen, so dass sie sowohl räumlich als auch zeitlich eingeordnet werden können. Hier soll nur auf die zeitliche Einordnung eingegangen werden.
Aktiviert man am unteren Ende des Programmfensters in Gephi die Timeline kann ein bestimmter Zeitintervall für die Anzeige ausgewählt werden.

Abbildung 23: Gephi mit aktivierter Timeline.
In der Abbildung ist zu erkennen, dass die Daten insgesamt einen Zeitraum vom 31.12.1173 bis zum 25.10.1478 umfassen. Zunächst sind alle Jahre ausgewählt, so dass alles angezeigt wird. Schränkt man die Auswahl mit Hilfe des Zeitbalkens am unteren Fensterrand jedoch ein, werden nur noch jene Edges angezeigt, deren Datumsangabe innerhalb des ausgewählten Intervalls liegen.
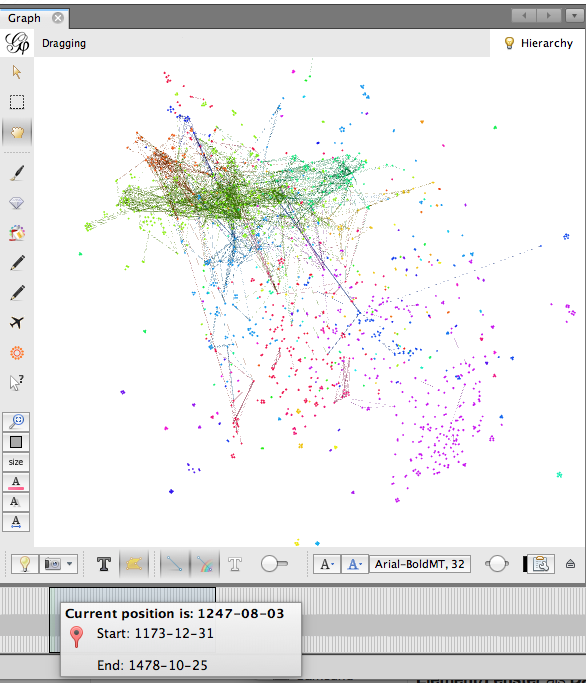
Abbildung 24: Gephi Timeline mit Auswahl von ca. 50 Jahren.
Je nach Fragestellungen lassen sich hier also Netzwerkstrukturen für bestimmte Zeiträume visualisieren. Es ist auch möglich, ein ausgewähltes Zeitintervall über den gesamten Zeitraum quasi filmartig ablaufen zu lassen, jedoch lässt sich dieses Feature hier im gedruckten Werk nicht darstellen[12].
5 Zusammenfassung
In diesem Aufsatz wurde gezeigt, wie man Informationen aus dem Register eines gedruckten Urkundenbuchs aus der Mitte des 19. Jahrhunderts mit Software zur Netzwerkanalyse visualisieren und untersuchen kann. Der Aufsatz schildert nur erste Schritte, verdeutlicht aber, dass es sich um einen interessanten Ansatz handelt. Die meisten Editions- und Regestenwerke besitzen Register, die mit vertretbarem Aufwand computerlesbar und der Netzwerkanalyse zugänglich gemacht werden können. Damit bieten sie eine neue Sicht auf das zu Grunde liegende Quellenmaterial, eröffnen neue Forschungsperspektiven und führen auch zu neuen Erkenntnissen, die vorher nicht sichtbar waren. Der hier geschilderte Ansatz führt jedoch nicht zu einer „Antwort-Maschine“, die dem Historiker die Arbeit abnimmt. Vielmehr können sich dem geschulten Auge in den Visualisierungen neue Interpretationsmöglichkeiten des Quellenmaterials bieten, die den Blick auf interessante Zusammenhänge in den Quellen lenken, welche vorher einfach auf Grund der Datenmasse nicht sichtbar gemacht werden konnten.
[1] https://www.youtube.com/watch?v=N3yv5E-hjbc abgerufen am 18.12.1014.
[2] https://www.youtube.com/channel/UCLHGQJIALL6Bz93F6nYQeEg abgerufen am 18.12.2014.
[3] https://gephi.github.io abgerufen am 18.12.2014.
[4] Hinweise auf die Bedeutung eines Kanzleivermerks.
[5] Urkundenbuch des Klosters Arnsburg in der Wetterau. Baur, Ludwig [Bearb.]. Baur, Ludwig [Hrsg.]. - Darmstadt (1849 - 1851)
[6] Meinem Kollegen Hans-Werner Bartz aus Mainz möchte ich an dieser Stelle ganz herzlich für die Unterstützung bei diesem Projekt danken.
[7] Vgl. http://gexf.net/format/. Eine Einführung in gexf findet sich unter: http://gexf.net/1.2draft/gexf-12draft-primer.pdf.
[8] Für die Unterstützung bei der Umwandlung der Textdatei in das gexf-Format möchte ich mich bei meinem Kollegen Ulli Meybohm herzlich bedanken.
[9] Bei Dreise handelt es sich um den Ausstellungsort, das im Urkundenbuch genannte Datum 1198 wurde auf 1174-01-01 normalisiert.
[10] Nähere Informationen zur Installation von Gephi finden Sie hier: https://gephi.github.io/users/install/
[11] Unter Windows kann man mit dem Mausrad in das Quadrat zoomen, bei MacOS mit zwei Fingern über das Mousepad streichen.
[12] Wie bereits oben erwähnt können Sie sich die Gehpi-Präsentation auch auf Youtube unter https://www.youtube.com/watch?v=oZD6GwedbtY ansehen.
Zitationsempfehlung/Suggested citation: Andreas Kuczera: Digitale Farbenspiele oder nützliches Werkzeug – Visualisierung von Netzwerken aus den Registern von Editions- und Regestenwerken, in: Mittelalter. Interdisziplinäre Forschung und Rezeptionsgeschichte, 8. Januar 2015, http://mittelalter.hypotheses.org/5089 (ISSN 2197-6120).
Big Data History
Der Blick zurück — als ich promovierte
Als ich Ende der 90er Jahre des letzten Jahrtausends meine Promotion zur Grundherrschaft eines Klosters in Mittelhessen begann, stand am Anfang die systematische Untersuchung der Überlieferung. Alle für den untersuchten Zeitraum relevanten Urkunden habe ich mindestens einmal gelesen und den Inhalt auf Relevanz für meine Arbeit untersucht. Zu dieser Zeit waren digitalisierte Volltexte und Quellen noch die Ausnahme. Heute, gut 15 Jahre später, stehen Historiker vor einer anderen Situation. Sie haben Zugriff auf eine immer weiter wachsende Anzahl an Volltexten und digitalen Quellen, Metadaten usw.
Bei der Digitalisierung lag der Fokus zu Beginn noch auf der Imagedigitalisierung mit entsprechenden Metadaten. Selbst die MGH stellten ihre digitalisierten Buchseiten zunächst als Scans im Netz bereit, ohne direkten Zugriff auf die Volltexte zu bieten. Auch die Regesta Imperii, die von 2001 bis 2006 im Rahmen eines DFG-Projekts digitalisiert wurden, standen vor der Frage, wie die Texte im Netz dargeboten werden sollten1. Ich selbst war damals Mitarbeiter in diesem Projekt und wir entschieden uns für eine Volltextdarstellung, die dem Buch möglichst nahe kommen sollte. Vor allem aber war eine Volltextdarstellung über HTML wesentlich leichter zu implementieren als die Präsentation von Scans mit dahinter verstecktem Volltext, wie sie zeitweise von den MGH angeboten wurde.
Neue Rezeptionsmöglichkeiten und der Ausgleich buchtechnischer Nachteile
Der DFG-Antrag hob u.a. hervor, dass mit dem Digitalisierungsvorhaben zum einen buchtechnische Nachteile ausgeglichen und zum anderen neue Rezeptionsmöglichkeiten erschlossen werden sollten. Dabei bezog sich der Hinweis auf buchtechnische Nachteile beispielsweise auf die Abteilungen 7 (Ludwig der Bayer) und 13 (Friedrich III.), die im Unterschied zu den “regulären” Regesta Imperii-Bänden nicht die komplette Überlieferung, sondern jeweils mit einem Heft den Quellenbestand eines Archivs oder einer Archivlandschaft enthalten. Dies führt dazu, dass man für die Recherche eines bestimmten Zeitraumes parallel alle bisher publizierten Hefte durchsehen muss, was offensichtlich großen Arbeitsaufwand mit sich bringt. Heute sind solche Recherchen mit einer Suchanfrage im Regestenmodul wesentlich leichter möglich. Auch die Bereitstellung einer Volltextsuche über die Regesta Imperii hat sicherlich den einen oder anderen Historiker auf Spuren gebracht, die er mit der alleinigen Analyse der gedruckten Bände möglicherweise nicht entdeckt hätte.
Nutzerverhalten und Nutzerperspektive
Im Rahmen eines Vortrages auf der “Digital Diplomatics 2013″ im November letzten Jahres in Paris stellten meine Kollege Torsten Schrade und ich u.a. einige Analysen zum Nutzerverhalten des Regestenmodules der Regesta Imperii Online vor.

Anzahl der Treffer im Regestenmodul der Regesta Imperii Online (Quelle: Digitale Akademie, Mainz — www.digitale-akademie.de).
Datengrundlage waren die anonymisierten Daten von Suchanfragen aus dem Zeitraum von November 2012 bis Ende Oktober 2013. Bei jeder Suchanfrage wurde auch die Anzahl der erzielten Treffer mitgeloggt. Die Abbildung zeigt nun in einem Tortendiagramm wieviele der ca. 101.000 Nutzeranfragen im Regestenmodul 0 bis 10 Treffer, wieviele 11 bis 20, 21-30 usw. bis zu mehr als 100 Treffer erzielt haben. Es zeigt sich unter anderem, dass sich die Nutzer des Regestenmodules von ihren Ergebnissen her grob in drei Gruppen einteilen lassen. Die erste Gruppe nutzt die Expertensuche des Regestenmoduls optimal aus und bekommt in der Regel auf eine Anfrage zwischen 1 und 10 Regesten zurückgemeldet. Diese können dann am Bildschirm gelesen, gedruckt oder sonst weiter verarbeitet werden. Eine zweite Nutzergruppe bekommt zwischen 10 und 100 Treffern. Die dritte Gruppe erhält auf ihre Anfrage 100 oder mehr Treffer.
Erhält man bei der Regestensuche 1 bis 10 Treffer ist das Ergebnis mit vertretbarem Aufwand lesbar und zu überprüfen. Bei über 10 bis 100 Treffern würde ich vermuten, dass diese Nutzer versucht sein könnten, ihre Suchkriterien zu verschärfen und damit ein besseres (in diesem Fall auch kleineres) Ergebnis zu erhalten. Die dritte Gruppe erhält 100 oder mehr Treffer, deren Auswertung am Bildschirm äußerst mühselig ist.
Zu der letzten Gruppe gehören oft auch Nutzer, die mit einen einzigen Suchbegriff ohne weitere einschränkende Angaben sehr viele Treffer zurückgeliefert bekommen. Diese Gruppe hat aus meiner Sicht den “Google-Anspruch” bei minialem Input in die Suchmaske optimale Ergebnisse zu erhalten. Selbstverständlich kann man hier einwenden, dass Nutzer eines Quellenportals zumindest rudimentäre inhaltliche Kenntnis des untersuchten Gegenstandes, hier also der Regesta Imperii, mitbringen sollten.
Was mich bei den Ergebnissen aber erstaunte, war die Nutzungsform der Regestensuche. Die meisten Nutzer wussten genau, was sie suchten. Sie wählten die Bandansicht, riefen einen Band auf und suchten sich das gewünschte Regest. Sie nutzten die Onlineregesten in der gleichen Weise wie einen gedruckten Regestenband — nur kamen sie schneller ans Ziel. Den neuen Rezeptionsmöglichkeiten, wie einst im DFG-Antrag formuliert, entsprach dies aber sicherlich nicht.
Bei der Diskussion im Kollegenkreis über die Ergebnisse war der Hinweis auf die mangelnde inhaltliche Kompetenz der Nutzer ein häufiger Reflex. Zunächst reagierte ich ebenso und machte die fehlende Kenntnis über die Regesta Imperii für die hohen Treffermengen verantwortlich. Dann aber fiel mir auf, dass die Nutzer mit “Google-Anspruch” mit ihren hohen Treffermengen vielleicht einfach eine neue Nutzungsform unseres Online-Materials formulieren.
Bisher folgt auf die Suche nach “Heinrich”, welcher der meistgesuchte Begriff in den RI ist, die Anzeige:2
Sie suchten nach ‘Heinrich’
Ihre Suche erzielte 17101 Treffer, ausgewählt wurden die 1000 relevantesten Regesten.
Sie sehen die Treffer 1 bis 20. Zur Verfeinerung Ihres Ergebnisses modifizieren Sie Ihre Suchabfrage.
Man könnte die Suchmöglichkeiten vielleicht dahingehend ergänzen, dass dem Nutzer bei der Suche nach ‘Heinrich’ folgendes angeboten wird:
“Sie suchten nach ‘Heinrich’
Sie haben 17.101 Treffer. Möchten Sie für die Einschränkung der Treffermenge eine Visualisierung der Trefferliste in chronologischer oder geographischer Form oder die Anzeige der Treffer pro Abteilung der Regesta Imperii ?“
Mit neuen Visualisierungsmethoden und einem transparenten Drill-Down3 könnten neue Blicke auf bereits vorhandenes digitales Material möglich werden.
Die kritische Masse
In den letzten Jahren haben die als digitale Volltexte zur Verfügung stehenden Quellen stark zugenommen. Neben den Regesta Imperii werden im Akademienprogramm4 immer mehr Projekte digitalisiert und im Netz bereitgestellt. Bei Neuanträgen im Akademienprogramm muss ein Abschnitt zur Bereitstellung der Forschungsergebnisse im Internet enthalten sein. Diese Bemühungen für eine breite Digitalisierung von Forschungsmaterialien haben in den letzten Jahren dazu geführt, dass wir langsam eine “kritische Masse” überschritten haben5. Und hier würde ich wieder zum “Google-Anspruch” aus dem letzten Absatz zurückkehren. Könnte es nicht neue Forschungsperspektiven aufzeigen, wenn wir große Datensammlungen gemeinsam untersuchen, sehr große Ergebnismengen erhalten und aus den anschließenden Visualisierungen oder mit anschließendem Drill-Down neuen Phänomenen oder Fragestellungen auf die Spur kommen, die wir aus analoger Perspektive nicht wahrgenommen haben ?
Visualisierung als Weg zu neuen Erkenntnissen
In meinem Beitrag zu Digitalen Perspektiven mediävistischer Quellenrecherche habe ich verschiedene Suchmasken von Online-Quellenportalen untersucht. Dabei konnte ich zeigen, dass die Suchmasken in der Regel optimale Möglichkeiten für die Einschränkung der Treffermenge auf eine zu handhabende Größe bieten. Dem gegenüber werden bei der Trefferanzeige kaum Möglichkeiten zur Weiterverarbeitung oder Visualisierung von großen Ergebnismengen geboten. Gerade hier liegt aber aus meiner Sicht eine große Chance für die Geschichteswissenschaften: die Untersuchung großer Quellenbestände im Sinne einer Big Data History, mit der Zusammenhänge aufgezeigt werden können, die im “analogen” Zeitalter nicht möglich waren.
Fazit
Momentan stehen wir noch an der Schwelle zu Big Data History. Es ist aber nur noch eine Frage der Zeit, bis gemeinsame Schnittstellen projektübergreifende Quellenanalyse möglich machen, die Ergebnisse visualisiert und weiterverarbeitet werden können und damit neue Blicke auf das Quellenmaterial möglich werden. Die Analyse großer Datenmengen bringt für den Historiker aber auch Herausforderungen mit sich. Bei großen Datenmengen stellt sich die Frage nach Fehlerabschätzungen, neuen Analysemethoden und theoretischen Ansätzen. Andererseits verspricht die Digitale Perspektive auf eine Big Data History interessante neue Blicke auf unser Quellenmaterial.
PDF-Download: Big_Data_History
- Zur Entwicklung des frühen Digitalisierungsprojekts vgl. Kuczera, Andreas: Die Regesta Imperii Online (2007) – In: Historisches Forum Bd. 10 (2007). Zum aktuellen Stand vgl. Weller, Tobias: Die Regesta Imperii Online (2014) – In: Rheinische Vierteljahrsblätter Bd. 78 (2014) S. 234-241; Würz, Simone: Mittelalterliche Quellen im Internet: Aspekte der Digitalisierung und Vernetzung der Regesta Imperii Online (2011) – In: Archive im Web – Erfahrungen, Herausforderungen, Visionen S. 162-171
- Vgl. http://www.regesta-imperii.de/regesten/suche.html abgerufen am 10.10.2014.
- https://de.wikipedia.org/w/index.php?title=Drill-Down&oldid=117104292
- Zum Akademienprogramm vgl. http://www.akademienunion.de/forschung/
- Ein Hinweis, dass wir die “kritische Masse” überschritten haben, war der Erfolg von http://codingdavinci.de/
Digitale Perspektiven mediävistischer Quellenrecherche
Zusammenfassung: Forschern in den Geisteswissenschaften stehen immer mehr digitalisierte Volltexte zur Verfügung. Daraus ergeben sich Chancen, neue Fragestellungen werden möglich, deren Beantwortung wiederum neue Perspektiven eröffnet, aber auch Herausforderungen schafft. In diesem Aufsatz wird versucht, diese Probleme einzugrenzen und neue Möglichkeiten für die Arbeit mit Volltexten in den Geisteswissenschaften mit einem Fokus auf die Mediävistik zu skizzieren.
Nutzerverhalten — Nutzerperspektiven
Der Zugang, den ein Forscher im Hinblick auf eine Fragestellung in der Mediävistik wählt, formt sich zumeist erst in der intensiven und direkten Auseinandersetzung mit den Quellen. Das Spektrum der Auseinandersetzung reicht dabei vom Studium und der Transskription des Originals hin zur Benutzung von Editionen oder Regestenwerken. Letztendlich aber stellt der Forscher meist engen Kontakt zu den Quellen her, indem er sie deutet, einordnet und mit den aus ihnen geschöpften Aussagen arbeitet. Zusammenfassende und erschließende Hilfsmittel bei Regesten- und Editionswerken sind, soweit vorhanden, Personen-, Orts- und Sachregister. Seit den 1990er Jahren gab es erste Anstrengungen maßgebliche Quellenbestände, Editionen und Regestenwerke im Volltext im Internet für die Recherche zur Verfügung zu stellen. Die zunehmende Verfügbarkeit der Volltexte änderte auch langsam die Herangehensweise an die Quellen: Die Volltextsuche ergänzte zunächst das gesamthafte Selbststudium aller für eine wissenschaftliche Fragestellung relevanten Quellen. Im Laufe der Zeit verschoben sich die Arbeitsschwerpunkte vom Studium der Einzelquellen hin zu Suchanfragen über die Volltextsuche. Damit einher geht der zunehmende Verlust des direkten Kontakts zur Quelle oder ihrer bearbeiteten Fassung in einer Edition. Das bedeutet bei den heutigen Studenten (und damit auch den zukünftigen Geschichtswissenschaftlern), dass sie eine Quelle in ihrer ursprünglichen Form sowie ihren Repräsentationen in einer Editionen immer weniger wahrnehmen da sie das Original oder die Editionsbände kaum noch zur Hand nehmen. Sie beschäftigen sich vielmehr mit Suchergebnissen, die ihren ursprünglichen Kontext der Quelle kaum noch deutlich werden lassen.
Andererseits können die neuen Möglichkeiten sie aber auch in die Lage versetzen, wesentlich größere Datenbestände gemeinsam zu durchsuchen und damit Fragestellungen aufzuwerfen, deren Behandlung einem Wissenschaftler unter den traditionellen „analogen“ Rahmenbedingungen allein auf Grund seiner beschränkten Lebenszeit und seines begrenzten Auffassungsvermögens gar nicht möglich war. Dies wird ohne Zweifel mittelfristig zu einem Perspektivenwechsel innerhalb der Geschichtswissenschaften führen, da neue Fragestellungen zu viel größer bemessene Quellenbestände möglich werden. So interessant die neuen Möglichkeiten für die Geschichtswissenschaften auch sein mögen, sind vor ihrer allgemeinen Akzeptanz doch noch methodische und qualitative Fragen zu klären.
Suchinterfaces — Ergebnisdarstellung: Nutzerperspektiven
 Vergleich von CIN (concrete information need) und POIN (problem-oriented information need) Suchansätzen.
Vergleich von CIN (concrete information need) und POIN (problem-oriented information need) Suchansätzen.Geht man zunächst vom Nutzer einer Suchmaschine aus, wird in den Fachwissenschaften zwischen CIN (concrete information need) und POIN (problem-oriented information need) unterschieden.1 In der Tabelle werden die beiden Ansätze auf einen fiktiven Nutzer der Regesta Imperii projiziert.2 Als kurze Erläuterung für die Tabelle hier noch zwei Beispiele: Eine Suchanfrage im Sinne von CIN ist z. B. die Suche nach einem Regest, wobei dem Nutzer Band und Regestennummer bekannt sind. Eine POIN-Suche würde z.B. die Verteilung von Nennungen der Kurfürsten in den Regesten Kaiser Friedrichs III. umfassen. Diese Kategorisierungen beschreiben nicht vollständig alle Suchstrategien der Nutzer der Regesta Imperii Online, bilden aber zwei größere Nutzergruppen ab, deren Perspektiven in den folgenden Betrachtungen berücksichtigt werden sollen.
Beispiele zu Suchinterfaces von mediävistischen Quellenportalen
Den Zugang zu digitalen Quellen im Bereich Mediävistik gewähren unter anderem die Suchinterfaces von Editions- und Regestenprojekten. In einem ersten Schritt werden daher exemplarisch die Suchmasken von vier verschiedenen Projekten untersucht und verglichen.3 . In einem zweiten Schritt werden die Funktionen für die Anzeige der Ergebnisse näher betrachtet.
 Expertensuche der Regesta Imperii Online (www.regesta-imperii.de).
Expertensuche der Regesta Imperii Online (www.regesta-imperii.de).Regesta Imperii
Die Online-Regestensuche der Regesta Imperii Online zeigt zunächst nur einen einfachen Suchschlitz an, um dem allgemeinen Nutzer einen möglichst flachen Einstieg zu ermöglichen. Die Expertensuche bietet dagegen wesentlich mehr Möglichkeiten, die Suche weiter einzuschränken und ermöglicht es, die Treffermenge auf ein zu bewältigendes Maß zu reduzieren. Inbesondere können flexibel mehrere Stichworte mit und/oder/nicht als Phrase oder auch als Ausstellungsort gesucht werden. Als Einstieg steht an prominenter Stelle eine umfangreiche Hilfeseite zur Verfügung.
Papstregesten
Ähnlich strukturiert zeigt sich die Expertensuche des Göttinger Akademienprojekts zu den mittelalterlichen Papsturkunden. Es vereint eine einfache Suche und die Expertensuche auf einer Seite. Bis zu vier und/oder/und nicht-Verknüpfungen von Stichworten verschiedener Kategorien sind möglich.
 Das Suchinterface des Göttinger Papsturkundenprojekts (www.papsturkunden.de).
Das Suchinterface des Göttinger Papsturkundenprojekts (www.papsturkunden.de).Die Freitextsuche muss erst explizit in der Suchkategorisierung angewählt werden, voreingestellt sind Person, Ort etc. Zudem kann man die Suche trunkieren oder nach bestimmten Datumsangaben suchen, wobei aber zwingend ein Suchwort anzugeben ist. Eine kurze Erläuterung am Fuß der Seite gibt Hinweise zu den Suchformaten für Trunkierung oder Datumseinschränkungen, wobei sich letztere allerdings nicht sehr leicht erschließen. Zweifelos von Vorteil sind die zahlreichen durchsuchbaren Kategorien, die auf eine gut strukturierte Datengrundlage schließen lassen4 Interessant wäre hier in jedem Fall die Darstellung der kategorisierenden Begriffe, um dem Nutzer einen Überblick zu den vorkommenden Orten, Personenkreisen etc. zu bieten.
dMGH
 Das Suchinterface der MGH (www.dmgh.de).
Das Suchinterface der MGH (www.dmgh.de).Das Suchinterface der dMGH bietet nur ein Suchfeld für Stichwörter aber dieses bringt interessante Funktionalitäten mit sich: Es liefert eine Vorschau auf mögliche Stichwörter und bietet dem Nutzer Einblicke in die vorhandenen Stichwortlisten. Diese Funktion zeigt dem Nutzer vorkommende Schreibformen an und sensibilisiert ihn für die Stärken und Schwächen einer Volltextsuche. Auf den Hilfeseiten werden die nicht direkt aus dem Suchformular heraus erkennbaren Suchfunktionen erklärt.
 Das Suchinterface der Deutschen Inschriften (www.inschriften.net).
Das Suchinterface der Deutschen Inschriften (www.inschriften.net).Deutsche Inschriften Online
Unter www.inschriften.net findet man den Internetauftritt des Akademienprojekts “Die Deutsche Inschriften”. Das Projekt bietet einen Google-Suchschlitz und auch eine Expertensuche, die nach Bänden, Zeiträumen etc. einschränken kann. Besonders gelungen sind auf dieser Seite die Tipps zur Suche, die informativ und kurz über die Suchmöglichkeiten informieren. So kann man z. B. mit Hilfe der Strg-Taste mehrere Bände auswählen und damit verbunden einen Zeitraum nach Treffern absuchen.
 Zusammenfassung der Ergebnisse.
Zusammenfassung der Ergebnisse.
In der nebenstehenden Tabelle sind nochmal die verschiedenen Suchmöglichkeiten der Seiten zusammengestellt. Einige Suchmöglichkeiten sind bei allen Projekten gleich, andere sind jeweils auf die Eigenschaften des präsentierten Materials zugeschnitten und spiegeln die Struktur der zugrundeliegenden Daten wider. Alle Suchinterfaces bringen einen Nutzer, der sich mit dem Material auskennt, sehr schnell dem gewünschten Ziel näher. Zusammengefasst kommen hier Experten mit CIN-Anfragen sehr schnell zum Ziel.
Ergebnisdarstellung
 Ergebnisanzeige der Regesta Imperii
Ergebnisanzeige der Regesta ImperiiAnders sieht dies für Benutzer mit POIN-Anfragen aus. Im Gegensatz zu CIN-Nutzern können oder wollen sie das durchsuchte Material nicht zu stark eingrenzen, da sie einen Überblick zu den Treffern ihrer Suchanfrage erhalten möchten. Für POIN-Anfragen spielt also die Anzeige der Trefferliste eine wichtige Rolle.
Regesta Imperii: Die Regesta Imperii Online bieten bei der Ergebnisanzeige die Möglichkeit nach Datum, Herrschername und Regestennummer aufsteigend und absteigend zu sortieren. Die Zahl der pro Seite angezeigten Treffer kann auf 10, 20, 50 und 100 Treffer eingeschränkt werden. Zusätzlich wird die Ergebnisliste per Voreinstellung auf die 10.000 relevantesten Treffer beschränkt.5 Große Treffermengen lassen sich über die o.a. Möglichkeiten hinaus nicht weiter strukturieren.
 Die Trefferanzeige der Papsturkunden.
Die Trefferanzeige der Papsturkunden.Papsturkunden: Die Ergebnisse im Göttinger Papsturkunden-Projekt werden in einer zweispaltigen Liste angezeigt, deren Sortierung sich nicht sofort erschließt. Nach meinem bisherige Kenntnisstand lässt sich die Reihung nicht beeinflussen. Große Treffermengen lassen sich hier nur schwer verarbeiten.
dMGH: Die dMGH bieten bei der Trefferliste die Möglichkeit nach Relevanz, Jahr, Titel und Band/Sortierschlüssel auf- und absteigend zu listen und zeigt schlussendlich das jeweilige Druckbild der Trefferseite an.6 Darüber hinaus kann die Ergebnisliste per Facettierung eingeschränkt werden. Außerdem bieten die Angaben zu den einzelnen Facetten erste Hinweise auf die zeitliche, räumliche und inhaltliche Verteilung.
 Ergebnisanzeige der dMGH mit Facettierungen rechts.
Ergebnisanzeige der dMGH mit Facettierungen rechts.Im einzelnen werden als Facetten angeboten:
- Abteilung (Treffervorkommen in den Abteilungen der MGH)
- Reihe (Treffervorkommen in den Reihen der MGH)
- Autor/Herausgeber
- Jahr (Treffer pro Jahr) Erscheinungsjahr des Bandes
- Automatische Personenerkennung (Liste der vorkommenden Personen nach Häufigkeit)
- Automatisch Ortserkennung (Deutsch) (Liste der Orte nach Häufigkeit)
Die Durchsicht der automatisch erkannten Personen- und Ortsnamen brachte zwar einige Fehler, ist an sich aber ein interessantes Hilfsmittel.
 Trefferdarstellung der Deutschen Inschriften (www.inschriften.net).
Trefferdarstellung der Deutschen Inschriften (www.inschriften.net).Deutsche Inschriften: Bei den Deutschen Inschriften gibt es in der Expertensuche die Möglichkeit die Anzeige der Treffer nach Datum, Landkreis/Stadt und Standort, auch in verschiedenen Kombinationen, zu sortieren. Die Treffenanzeige selbst lässt sich nicht weiter beeinflussen und bietet bei großen Treffermengen keine Möglichkeiten der Ergebnisstrukturierung.
Ergebnis: Werden die Suchkriterien so gewählt, dass im Anschluss die Trefferliste nicht zu groß wird, sind alle Seiten gut nutzbar. Nutzer mit CIN-Anfragen bekommen in kürzester Zeit Ergebnisse, mit denen sie weiter arbeiten können. Nutzer mit POIN-Anfragen haben es dagegen deutlich schwerer aus größeren Treffermengen Strukturen und Ansätze für die Fokussierung auf ihre Fragestellung herauszulesen. Lediglich bei den dMGH werden interessante Facettierungsansätze und auch die automatische Identifizierung von Personen und Orten gezeigt, deren Ausbau im Hinblick auf geographische und grafische Darstellung wünschenwert wäre.
Mehrfach-Facettierendes Suchinterface – der Spaziergang durch den Informationsdschungel
 Beispiel für eine facettierte Trefferanzeige (http://www.e-codices.unifr.ch/de)
Beispiel für eine facettierte Trefferanzeige (http://www.e-codices.unifr.ch/de)Datenbankbasierte Facettierungen: Facettierte Suchinterfaces finden heute in den Onlineshops Anwendung und bieten dem Nutzer die Möglichkeit, große Treffermengen nach vorgegebenen Kriterien einzugrenzen. Dabei werden Facettierungen angeboten, die in der Regel in der zu Grunde liegenden Datenbank bereits vorhanden sind, wie z.B. der Preis des Produkts, Hersteller etc. Als Beispiel für die Implementierung einer facettierten Ergebnisanzeige ist in der Abbildung links die Seite http://www.e-codices.unifr.ch/de dargestellt, auf der am rechten Rand die Suchergebnisse einzelnen Facetten zeitlicher und inhaltlicher Art zugeordnet werden. Dieser Ansatz für die Trefferanzeige wäre für Nutzer mit POIN-Anfragen interessant, da hier eine große Treffermenge nicht abschreckt sondern auch überblicksartig den Blick aus anderen Perspektiven eröffnet. Für die Regesta Imperii wären als Facettierungsmöglichkeiten z. B. die Datumsangaben der Regesten, die Ausstellung inkl. Geo-Koordinaten und die Verteilung auf die verschiedenen Bände und Abteilungen denkbar. Eine Suchanfrage mit dem einzigen Suchbegriff Heinrich und den damit verbundenen über 17.000 Treffern könnte damit nicht nur in zeitlicher und räumlicher Perspektive sondern auch im Hinblick auf die den Regesta Imperii zugrunde liegende Projektstruktur visualisiert werden, indem zeitliche und räumliche Häufungen sichtbar werden.
Nutzer-beeinflusste Facettierungen: Die eben betrachteten Facettierungen beruhen auf den bereits in der Regestendatenbank der Regesta Imperii vorhandenen Datenstrukturen und könnten durch weitere, vom Nutzer selbst formulierte Facettierungskriterien ergänzt werden. Zu denken ist hier z.B. an Kriterien aus der Computerlinguistik, Begriffshäufungen oder Distanz von Suchbegriffen, ggf. auch in Verbindung mit regulären Ausdrücken und Trunkierungen.
Fazit
Zusammenfassend bleibt festzustellen, dass die Digitalisierung von mittelalterlichen Quellen für den Forscher große Vorteile mit sich bringt. So ist der Zugriff auf die Quelle sehr viel schneller als zu “analogen” Zeiten möglich. Mit Hilfe ausgereifter Expertensuchmasken bieten die hier betrachteten Portale schnellen und umfassenden Zugriff auf das Material.
Für einen sinnvollen Umfang der Treffermengen ist bei allen Portalen in der Regel die Nutzung der Expertensuche mit hinreichend einschränkenden Suchkriterien notwendig (CIN-Suche). Für explorative Suchanfragen, die von sich aus größere Treffermengen ergeben sind die Ergebnisanzeigen dagegen weniger geeignet. Auch wenn solche explorativen Suchen sich auf verschiedene der hier untersuchten Datenbanken erstrecken gibt es keine Möglichkeit, die Treffermengen als Ganzes zu untersuchen.
Festzustellen ist, dass projektübergreifende Suchanfragen unter vertretbarem Aufwand nicht über Suchinterfaces der einzelnen Projekte zu realisieren sind. Vielmehr wäre ein zweigleisiges Vorgehen sinnvoll. Zum einen arbeiten die Projekte weiter an der Bereitstellung mediävistischer Quellen im Internet und stellen interssierten Nutzern Schnittstellen für ihre Datenbanken zur Verfügung. Zum anderen arbeiten national oder EU-weit gelagerte Projekte (wie z.B. DARIAH) an Tools, mit denen umfangreiche Abfrageergebnisse sinnvoll und transparent visualisiert werden können.
Wie sehr für viele die Nutzung von Google, sei es die Suchmaschine, Google-Maps oder andere Dienste im Alltag schon unentbehrlich geworden ist, können die meisten in einer kritischen Selbstreflexion ergründen. Google liefert oft bei geringem Aufwand einen sehr guten Überblick zu den Suchergebnissen, wobei der Weg zu den Ergebnissen nicht sehr transparent ist. Meine Vorstellung von “digitalen Perspektiven” wäre daher die Formulierung neuer Fragestellungen an die digitalisierten Quellen mit Hilfe moderner, transparenter Suchtechniken, ergänzt um leicht und intuitiv verständliche Visualisierungsmethoden.
Empfohlene Zitierweise:
Andreas Kuczera: Digitale Perspektiven mediävistischer Quellenrecherche, in: Mittelalter. Interdisziplinäre Forschung und Rezeptionsgeschichte, 18. April 2014, http://mittelalter.hypotheses.org/3492 (ISSN 2197-6120).
- Die CIN/POIN-Systematik wurde entwickelt von Frants, Valery I.; Shapiro, Jacob; Voiskunskii, Vladimir G.: Automated information retrieval: Theory and methods. Library and information science. San Diego: Academic Press 1997.
- Vgl. hierzu Wolfgang Stock, Information Retrieval: Informationen suchen und finden. München 2007, dessen Tabelle auf S. 52 als Vorlage diente.
- Eine intensive qualitative Analyse mit vergleichenden Suchanfragen an die verschiedenen Seiten würde den Rahmen dieser Untersuchung sprengen. Vielmehr standen beim Vergleich die dem Nutzer direkt dargeboteten Funktionen im Vordergrund.
- Im Einzelnen kann man nach z. B. Jaffé-Nr., Pontificia-Nr., Regesta-Imperii-Nr., Pontifiakt, Papstunterschrift, Notarsunterschriften, Zeugen, Siegel, Überlieferung, Diplomatischer Kommentar und Überlieferung filtern.
- Relevanz meint in diesem Fall die Relevanzkriterien der implementierten Suchmaschine SPHINX.
- Zu den Relevanzkriterien heißt es in der Hilfe: Die Relevanz berechnet sich durch die mathematische Ähnlichkeit von Suchanfrage und Dokument (hier Buch). Die Bedeutung einzelner Wörter hängt von ihrer Häufigkeit und der Größe des Dokumentes ab.